
😃 Welcome to my personal page!
I am Liao Shen (申立奥 in Chinese), a third-year (2023.09-) master’s student in Artificial Intelligence at Huazhong University of Science and Technology (HUST), supervised by Prof. Zhiguo Cao. Before that, I received my bachelor’s degree from HUST in 2023. Currently, I am fortunate to be a research associate at MMLAB@NTU, advised by Prof. Chen Change Loy. My research focuses on 3d computer vision, AI Generative Content (AIGC) and bokeh rendering.
🔥 News
- 2025-11 : 🎉 Cinectrl is now posted on Arxiv.
- 2025-10 : 🎉 IPRO is now posted on Arxiv.
- 2025-03 : 🎉 Free4D and MUGS are accepted to ICCV 2025.
- 2025-02 : 🎉 DoF-Gaussian and CH3Depth are accepted to CVPR 2025.
- 2024-10 : 🎉 Video Bokeh Rendering is accepted to ACM MM 2024, and is honored as best paper candidate🚀🚀🚀.
- 2024-07 : 🎉 DreamMover and MVSGaussian are accepted to ECCV 2024.
- 2024-07 : 🎉 Won Winner Award in “TRICKY 2024 Transparent & Reflective objects In the wild Challenge”.
- 2024-02 : 🎉 DyBluRF is accepted to CVPR 2024.
- 2023-10 : 🎉 Make-It-4D is accepted to ACM MM 2023.
- 2023-06 : 🎉 Won Winner Award in “NTIRE 2023 Bokeh Effect Transformation Challenge”.
📝 Publications

[Arxiv] Generative Photographic Control for Scene-Consistent Video Cinematic Editing
Huiqiang Sun*, Liao Shen*, Zhan Peng, Kun Wang, Size Wu, Yuhang Zang, Tianqi Liu, Zihao Huang, Xingyu Zeng, Zhiguo Cao, Wei Li, Chen Change Loy
[Paper]
Cinectrl is the first video cinematic editing framework that provides fine control over professional camera parameters (e.g., bokeh, shutter speed).

[Arxiv] Identity-Preserving Image-to-Video Generation via Reward-Guided Optimization
Liao Shen*, Wentao Jiang*, Yiran Zhu, Jiahe Li, Tiezheng Ge, Zhiguo Cao, Bo Zheng.
[Project page]
[Paper]
[Code]
IPRO is the first identity-preserving image-to-video generation model via reward feedback learning.

[ICCV 2025] MuGS: Multi-Baseline Generalizable Gaussian Splatting Reconstruction
Yaopeng Lou, Liao Shen, Tianqi Liu, Jiaqi Li, Zihao Huang, Huiqiang Sun, Zhiguo Cao.
[Paper]
MuGS is the first multi-baseline generalizable gaussian splatting method.

[ICCV 2025] Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency
Tianqi Liu, Zihao Huang, Zhaoxi Chen, Guangcong Wang, Shoukang Hu, Liao Shen, Huiqiang Sun, Zhiguo Cao, Wei Li, Ziwei Liu.
[Project page]
[Paper]
[Code]
[Video]
Free4D is a tuning-free framework for 4D scene generation from a single image or text.

[CVPR 2025] DoF-Gaussian: Controllable Depth-of-Field for 3D Gaussian Splatting
Liao Shen, Tianqi Liu, Huiqiang Sun, Jiaqi Li, Zhiguo Cao, Wei Li, Chen Change Loy.
[Project page]
[Paper]
[Code]
We introduce DoF-Gaussian, a controllable depth-of-field method for 3D-GS. We develop a lens-based imaging model based on geometric optics principles to control DoF effects. Our framework is customizable and supports various interactive applications.

[ACM MM 2024] Video Bokeh Rendering: Make Casual Videography Cinematic (Best paper candidate)🚀🚀🚀
Yawen Luo, Min Shi, Liao Shen, Yachuan Huang, Zixuan Ye, Juewen Peng, Zhiguo Cao.
[Paper]
We introduce VBR, the video bokeh rendering model that first leverages information from multiple frames to generate refocusable videos from all-in-focus videos.
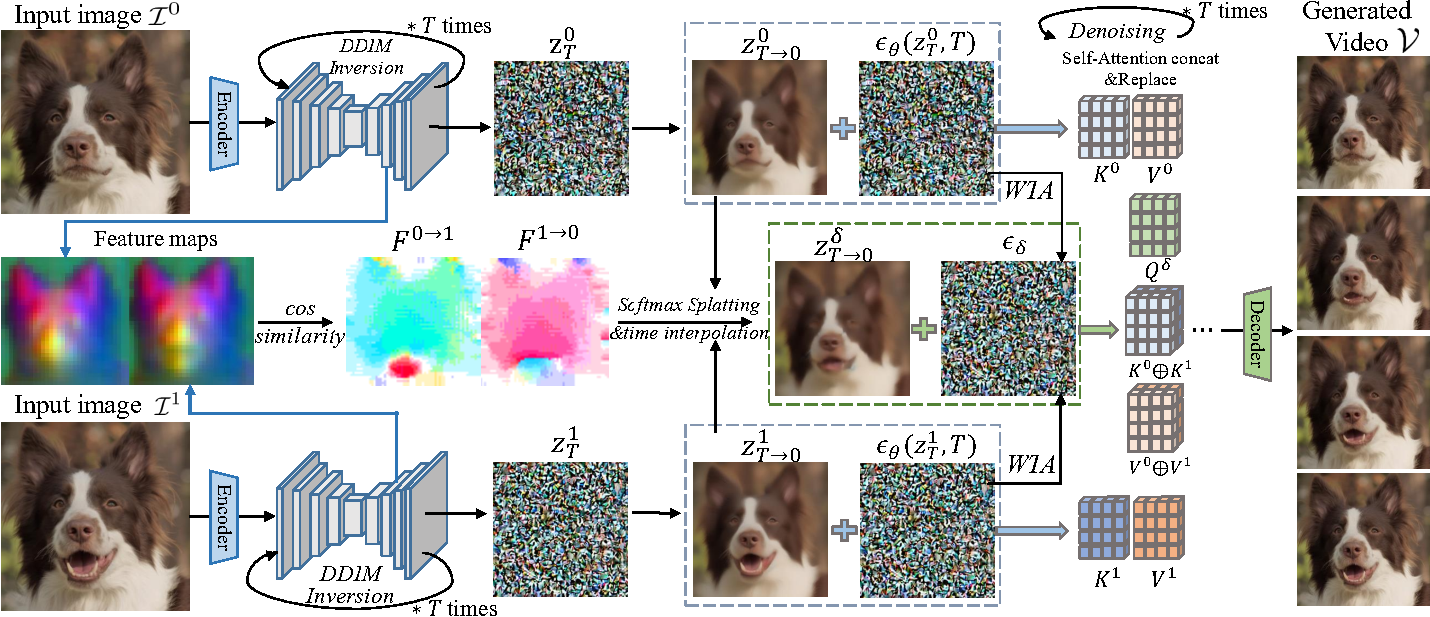
[ECCV 2024] DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion
Liao Shen, Tianqi Liu, Huiqiang Sun, Xinyi Ye, Baopu Li, Jianming Zhang, Zhiguo Cao.
[Project page]
[Paper]
[Code]
By leveraging the prior of diffusion models, DreamMover can generate intermediate images from image pairs with large motion while maintaining semantic consistency.

[ECCV 2024] MVSGaussian: Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
Tianqi Liu, Guangcong Wang, Shoukang Hu, Liao Shen, Xinyi Ye, Yuhang Zang, Zhiguo Cao, Wei Li, Ziwei Liu.
[Project page]
[Paper]
[Code]
MVSGaussian is a Gaussian-based method designed for efficient reconstruction of unseen scenes from sparse views in a single forward pass. It offers high-quality initialization for fast training and real-time rendering.

[CVPR 2024] DyBluRF: Dynamic Neural Radiance Fields from Blurry Monocular Video
Huiqiang Sun, Xingyi Li, Liao Shen, Xinyi Ye, Ke Xian, Zhiguo Cao.
[Project page]
[Paper]
[Code]
DyBluRF is a dynamic neural radiance field method that synthesizes sharp novel views from a monocular video affected by motion blur.

[ACM MM 2023] Make-It-4D: Synthesizing a Consistent Long-Term Dynamic Scene Video from a Single Image
Liao Shen, Xingyi Li, Huiqiang Sun, Juewen Peng, Ke Xian, Zhiguo Cao, Guosheng Lin.
[Paper]
[Code]
Make-It-4D is a novel framework that can generate a consistent long-term dynamic video from a single image. The generated video in volves both visual content movements and large camera motions, bringing the still image back to life.
🎖 Honors and Awards
- 2025 National Scholarship (Top 1%)
- 2024 National Scholarship (Top 1%)
- 2023 Honours Degrees (Top 3%)
- 2021 Outstanding Undergraduate Student (Top 1%)
- 2019 Merit Student (Top 7%)
📝 Internships and Experiences
- 2025.07 - 2025.12, Internship at Alibaba group, advised by Wentao Jiang and Tiezheng Ge.
- 2025.01 - 2025.06, Project Officer at MMLAB@NTU, advised by Prof. Chen Change Loy.
- 2024.06 - 2025.02, Worked on project “Camera Image Fusion and Reconstruction” with Huawei.
- 2023.12 - 2024.05, Worked on project with Adobe.
- 2023.10 - up to now, Work on project “Large Aperture Bokeh Effect Simulation of DSLR” with Vivo.
📎 Links
- Personal Pages: https://leoShen917.github.io (updated recently🔥)
- Google Scholar: https://scholar.google.com/citations?user=bEi3j64AAAAJ
- CV: https://leoShen917.github.io/assets/pdf/leo_cv.pdf